Walkthrough Tutorial: Modelling Emergent Communication
This walkthrough tutorial accompanies Section 4.3 of the following paper:
Authors. (submitted). PyFCG: Fluid Construction Grammar in Python.
This tutorial exemplifies the primary use case of FCG: implementing the linguistic capability of autonomous agents in agent-based models of emergent communication. In such experiments, agents start out with an empty grammar and gradually build up their linguistic knowledge as they take part in situated communicative interactions with other agents in the population. This tutorial presents a PyFCG-powered implementation of a neuro-symbolic version of the seminal naming game experiment, in which a population of agents converges on a naming convention for referring to entities that they observe in their environment. The tutorial showcases the integration of PyFCG with other widely used Python libraries, including PyTorch, NumPy and scikit-learn.
Initialisation
The first time you run this notebook, you might need to install a number of Python modules in your environment:
[ ]:
# Ensure to upgrade to the latest version of pyfcg
! pip install --upgrade pyfcg
# Machine learning / neural networks
! pip install numpy
! pip install torch
! pip install scikit-learn
# Visualisation
! pip install matplotlib
! pip install alive_progress
# Downloading benchmark data
! pip install kagglehub
We can now load Python modules and initialise PyFCG:
[1]:
import pyfcg as fcg
import random
import numpy as np
import matplotlib.pyplot as plt
import torch
from torch import nn
from torch.optim import Adam
from torch.utils.data import TensorDataset
from sklearn.model_selection import train_test_split
import os
import alive_progress
import kagglehub
# force_download=True ensures that you have the latest version of the underlying fcg-go software,
# (you only need to do this once, afterwards you can set force_download to False)
fcg.init(force_download=False)
If your device supports cuda or mps, you can use your GPU for dealing with neural networks. If not, everything will run on your CPU:
[2]:
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "mps" if torch.mps.is_available() else "cpu")
DEVICE
# If you have CUDA or MPS, but your graphical card is very limited in memory, you might still need to use 'cpu'Adam
# DEVICE = 'cpu'
[2]:
device(type='mps')
A World of Faces
A first step in setting up a grounded naming game experiment concerns the creation of a world in which the agents will operate. In this case, the world consists of 2000 mugshots of 40 individual people, adopted from the Augmented Olivetti Faces Dataset.
We first define a general class GroundedNGWorld, and a few methods for sampling and visualising scenes:
[3]:
class GroundedNGWorld:
"""
A general class for creating worlds that can be used in Grounded Naming Game experiments.
"""
def __init__(self, train_data, train_targets, test_data, test_targets):
""" Initialise train and test data and labels, and create dictionaries with
the labels as keys and the corresponding data instances as values."""
self.train_data = train_data
self.train_targets = train_targets
self.test_data = test_data
self.test_targets = test_targets
self.train_per_individual = sort_data_per_individual(self.train_data, self.train_targets)
self.test_per_individual = sort_data_per_individual(self.test_data, self.test_targets)
def sample_scene_with_unique_target(self, nr_of_entities=5, train=False):
""" Sample a new scene consisting of a number of entities
(nr_of_entities), each of a different type, which are draw from the test set (unless train is set to True).
One entity is selected as the target of the conversation, and its index is returned as a second return value."""
scene = []
if train is True:
individuals = self.train_per_individual
else:
individuals = self.test_per_individual
remaining_individuals = list(individuals.keys())
target_type = random.choice(remaining_individuals)
target = random.choice(individuals[target_type])
remaining_individuals.remove(target_type)
for i in range(1, nr_of_entities):
# Randomly pick a type
distractor_type = random.choice(remaining_individuals)
# Randomly pick a data instance for the chosen type
scene.append(random.choice(individuals[distractor_type]))
remaining_individuals.remove(distractor_type)
scene.append(target)
random.shuffle(scene)
# Retrieve the target index from the scene:
scene_as_list = [arr.tolist() for arr in scene]
target_index = scene_as_list.index(target.tolist())
return scene, target_index
def sort_data_per_individual(images, labels):
"""Group images based on their target label."""
per_individual = {}
for i in range(0, len(images)):
if labels[i] in per_individual.keys():
per_individual[labels[i].item()].append(images[i])
else:
per_individual[labels[i].item()] = [images[i]]
return per_individual
def visualise_image(image):
"""Show image visually in grayscale."""
img = image.squeeze()
plot = plt.imshow(img, cmap='gray')
return plot
def visualise_scene(scene):
"""Show scene visually in grid."""
plt.figure(figsize=(11, 18))
for index, image in enumerate(scene):
plt.subplots_adjust(bottom=0.3, right=0.8, top=0.5)
ax = plt.subplot(3, 5, index + 1)
ax.axis('off')
ax.set_title('entity ' + str(index), fontdict={'fontsize': 8})
visualise_image(image)
We download the Olivetti augmented faces dataset from Kaggle:
[4]:
olivetti_dataset_path = kagglehub.dataset_download("martininf1n1ty/olivetti-faces-augmented-dataset")
print("Path to dataset files:", olivetti_dataset_path)
Path to dataset files: /Users/paul/.cache/kagglehub/datasets/martininf1n1ty/olivetti-faces-augmented-dataset/versions/2
We subclass from GroundedNGWorld and implement functionality specifically for dealing with the Olivetti dataset. Essentially, the code below creates train and test splits, and specifies how to represent and train a neural module that classifies mugshots into individuals.
[5]:
class OlivettiLgData(GroundedNGWorld):
"""
Class holding augmented Olivetti dataset for language games.
"""
def __init__(self):
"""Initialise a new Olivetti world of faces for playing language games."""
images = np.load(olivetti_dataset_path + '/augmented_faces.npy').reshape(-1, 1, 64, 64)
targets = np.load(olivetti_dataset_path + '/augmented_labels.npy')
# 80% of the data set is used for training, the remaining 20% for testing:
train_images, test_images, train_labels, test_labels = train_test_split(images, targets, test_size=0.2, random_state=42)
# Turn numpy arrays into tensors for working with PyTorch:
train_images = torch.tensor(train_images, dtype=torch.float32)
test_images = torch.tensor(test_images, dtype=torch.float32)
train_labels = torch.tensor(train_labels)
test_labels = torch.tensor(test_labels)
# Call superclass initialisation for the Olivetti dataset:
super().__init__(train_images, train_labels, test_images, test_labels)
class DescribeNetOlivetti(nn.Module):
"""
Neural module that classifies faces into individuals.
"""
def __init__(self, input_dim=1,hidden_dim=512,output_dim=40,kernel_size=3,stride=(1,1),pooling_size=2):
super().__init__()
self.initialize_weights()
self.conv1 = nn.Conv2d(
in_channels=input_dim,
out_channels=hidden_dim,
kernel_size=kernel_size,
stride=stride,
padding=1,
device=DEVICE,
dtype=torch.float32
)
self.conv2 = nn.Conv2d(
in_channels=hidden_dim,
out_channels=hidden_dim,
kernel_size=kernel_size,
stride=stride,
padding=1,
device=DEVICE,
dtype=torch.float32
)
self.conv3 = nn.Conv2d(
in_channels=hidden_dim,
out_channels=hidden_dim,
kernel_size=kernel_size,
stride=stride,
padding=1,
device=DEVICE,
dtype=torch.float32
)
self.maxpooling = nn.MaxPool2d(
kernel_size=pooling_size,
stride=pooling_size
)
self.flat = nn.Flatten()
self.relu = nn.ReLU()
self.dense_layer = nn.Linear(
in_features=hidden_dim * 32 * 32,
out_features=hidden_dim,
device=DEVICE,
dtype=torch.float32
)
self.output_layer = nn.Linear(
in_features=hidden_dim,
out_features=output_dim,
device=DEVICE,
dtype=torch.float32
)
def initialize_weights(self):
"""Randomly initialise the weights of the network."""
for layer in self.children():
if isinstance(layer, nn.Conv2d):
nn.init.xavier_uniform_(layer.weight)
if layer.bias is not None:
nn.init.zeros_(layer.bias)
elif isinstance(layer, nn.Linear):
nn.init.xavier_uniform_(layer.weight)
nn.init.zeros_(layer.bias)
def forward(self, x):
"""Forward pass through the network."""
x = self.conv1(x)
x = self.relu(x)
x = self.conv2(x)
x = self.relu(x)
x = self.conv3(x)
x = self.relu(x)
x = self.maxpooling(x)
x = self.flat(x)
x = self.dense_layer(x)
x = self.relu(x)
x = self.output_layer(x)
return x
def _train(self, training_features, training_labels,
validation_features, validation_labels,
nr_of_epochs, batch_size=32, learning_rate=0.00001):
"""Train the network."""
optimizer = Adam(self.parameters(), lr=learning_rate)
loss_fn = nn.CrossEntropyLoss()
train_split = TensorDataset(training_features, training_labels)
train_loader = torch.utils.data.DataLoader(train_split, batch_size=batch_size, shuffle=True)
print('Starting training for new agent.')
for epoch in range(nr_of_epochs):
# Train on all instances from the train loader:
self.train()
for images, labels in train_loader:
images, labels = images.to(DEVICE), labels.to(DEVICE)
optimizer.zero_grad() # Reset gradients
outputs = self(images) # Forward pass
train_loss = loss_fn(outputs, labels) # Compute loss
train_loss.backward() # Backward pass
optimizer.step() # Update weights
_, predicted = torch.max(outputs, 1)
correct = (predicted == labels).sum().item()
accuracy = correct / labels.size(0)
# Evaluate the current model on the validation set:
self.eval()
with torch.no_grad():
validation_features = validation_features.to(DEVICE)
validation_labels = validation_labels.to(DEVICE)
validation_ypred = self(validation_features)
val_loss = loss_fn(validation_ypred, validation_labels)
_, val_predicted = torch.max(validation_ypred, 1)
val_correct = (val_predicted == validation_labels).sum().item()
val_accuracy = val_correct / validation_labels.size(0)
if epoch % 1 == 0 or epoch == nr_of_epochs - 1:
print(
f"Epoch {epoch}: Training Loss = {train_loss.item():.4f} | Validation Loss = {val_loss.item():.4f} | Training Acc = {accuracy:.4f} | Validation Acc = {val_accuracy:.4f}")
A Population of Agents
We define our agents to be instances of a new class GroundedNGAgent that subclasses from PyFCG’s fcg.Agent class. The agents are thereby initialised with an empty grammar and inherit a collection of methods for interacting with instances of the fcg.Grammar and fcg.Construction classes.
[6]:
class GroundedNGAgent(fcg.Agent):
"""
Agent subclasses from fcg.Agent.
"""
def __init__(self, configuration):
"""Initialisation of agents upon creation."""
self.discourse_role = None
self.task = None
self.configuration = configuration
self.neural_modules = {}
self.utterance = None
self.concept = None
self.communicated_successfully = False
self.applied_cxn = None
self.competitor_cxns = []
# We call the init method of the fcg.Agent superclass
# to initialise the agent's grammar
super().__init__()
# We create a mapping for the agent's categories
# so it has its own internal system of categories
agent_id_index = self.id.find("-") + 1
agent_id_number = int(self.id[agent_id_index:])
self.category_mapping = {}
for i in range (0, configuration['nr_of_categories']):
self.category_mapping[i] = i * agent_id_number
def clear_for_interaction(self):
"""Initialisation of agents at the start of an interaction. """
self.discourse_role = None
self.task = None
self.utterance = None
self.applied_cxn = None
self.concept = None
self.communicated_successfully = False
def learn_neural_module(self, module_name, i, world):
"""Learn a neural module for the agent based on the world."""
# Create an instance of the image classifier model
network = eval(module_name + '()').to(DEVICE)
# Train the network for nr_of_epochs epochs with learning_rate
network._train(training_features=world.train_data,
training_labels=world.train_targets,
validation_features=world.test_data,
validation_labels=world.test_targets,
nr_of_epochs=self.configuration['nr_of_epochs'],
learning_rate=self.configuration['learning_rate'])
# Store the learned network in the models directory
os.makedirs('./models/', exist_ok=True)
torch.save(network.state_dict(), './models/' + module_name + '-' + str(i) + '.pt')
# Store the learnt network in the agent's inventory of neural_modules
self.neural_modules[module_name] = network
def load_neural_module(self, module_name, i):
"""Load pretrained neural module in agent."""
# Create an instance of the image classifier model
network = eval(module_name +'()').to(DEVICE)
# Load the neural network
network.load_state_dict(torch.load('./models/' + module_name + '-' + str(i) + '.pt', map_location=DEVICE))
# Store the loaded network in the agent's inventory of neural_modules
self.neural_modules[module_name] = network
def comprehend(self, utterance):
""" Comprehend utterance, collect meaning, applied_cxn and competitors."""
# Calls PyFCG's comprehend all method to get all possible meanings
# of the utterance according to the agent's grammar
meanings, applied_cxn_names_per_meaning = self.comprehend_all(utterance)
# The agent could not understand the utterance:
if meanings == [None]:
return None
# The agent could understand the utterance, we store the construction it applied and the alternative cxns as competitors
else:
self.applied_cxn = self.find_cxn_by_name(applied_cxn_names_per_meaning[0][0])
self.competitor_cxns = []
for cxn_names in applied_cxn_names_per_meaning[1:]:
self.competitor_cxns.append(self.find_cxn_by_name(cxn_names[0]))
return meanings[0]
def formulate(self, meaning):
"""Formulate an utterance given a meaning. Use the highest-scored cxn and collect the competing constructions on the go."""
# Call PyFCG's formulate all method to get all possible ways
# to formulate the meaning according to the agent's grammar
utterances, applied_cxn_names_per_utterance = super().formulate_all(meaning)
# The agent could not formulate the meaning with its grammar:
if utterances == [None]:
return None
# The agent could formulate an utterance, we store the construction it applied and the alternative cxns as competitors
else:
self.utterance = utterances[0][0]
self.applied_cxn = self.find_cxn_by_name(applied_cxn_names_per_utterance[0][0])
self.competitor_cxns = []
for cxn_names in applied_cxn_names_per_utterance[1:]:
self.competitor_cxns.append(self.find_cxn_by_name(cxn_names[0]))
return self.utterance
def learn(self, form, meaning):
""" Create a new cxn given a form and a meaning. """
new_cxn = fcg.Construction(name=form + '-cxn',
conditional_pole=[["?name-unit",
{"#meaning": [["concept", meaning]]},
{"#form": [
["sequence", '\"' + form + '\"', "?left", "?right"]]}]],
attributes={"object": meaning, "name": form, "score": 0.5})
self.add_cxn(new_cxn)
return new_cxn
def reward(self):
""" Reward through lateral inhibition. """
inc_delta = CONFIGURATION['cxn_positive_reward']
dec_delta = CONFIGURATION['cxn_negative_reward']
if self.communicated_successfully:
# If success, reward the applied cxn and punish the competitors
self.applied_cxn.increase_score(delta=inc_delta)
for competitor in self.competitor_cxns:
competitor.decrease_score(delta=dec_delta)
# Delete cxns that reach a 0 score
if competitor.get_score() <= 0.0:
self.delete_cxn(competitor)
else:
# If failure, speaker punishes applied cxn
if self.discourse_role == 'speaker':
self.applied_cxn.decrease_score(delta=dec_delta)
# Delete cxns that reach a 0 score
if self.applied_cxn.get_score() <= 0.0:
self.delete_cxn(self.applied_cxn)
Experiment
We also define a new experiment class GroundedNGExperiment. Three methods are associated to this class. The run_prelinguistic_stage method engages a prelinguistic stage during which each agent individually learns to tell people apart. Technically, each agent trains a neural network that learns to classify the bitmap images from a training portion of the dataset into 40 classes, i.e. one class per individual in the world. Agents can now quite reliably classify new mugshots in terms of
individuals, but the labels that they have learnt to associate to these individuals will differ. For example, mugshots of a given individual might be classified into class 7 by one agent, and into class 34 by another. The labels are not conventional and can thereby not be used by the agents as such for exchanging information about appearances of individuals in their environment.
After the prelinguistic stage, the agents in the population will participate in a series of situated communicative interactions, as implemented by the run_series method, during which they will converge upon a naming convention for communicating about new appearances of individuals. The run_series method iteratively calls the run_interaction method, which initiates a new communicative interaction as an instance of the DescribeAndPointInteraction class, makes the interaction happen
by calling its interact method, and records its outcome.
[7]:
class GroundedNGExperiment():
"""
The GroundedNGExperiment class holds the population and world and
defines methods to run (series of) communicative interactions.
"""
def __init__(self, configuration={}):
"""Upon initialisation, the world and population are created."""
# The configuration passed to the experiment is merged with the default configuration.
global CONFIGURATION
self.configuration = fcg.merge_dicts(CONFIGURATION,configuration)
# World and population are created.
self.world = eval(self.configuration['world'])
self.population = [GroundedNGAgent(self.configuration) for i in range(self.configuration['nr_of_agents'])]
self.current_interaction = None
# With a new experiment, we also reset the monitors
MONITORS = {}
def run_prelinguistic_stage(self, learn_prelinguistic_categorisation=None):
"""Initialise neural modules of the agents in the population."""
train = self.configuration['learn_prelinguistic_categorisation']
if learn_prelinguistic_categorisation is not None:
train = learn_prelinguistic_categorisation
for i in range(len(self.population)):
agent = self.population[i]
for module_name in self.configuration['neural_modules']:
if train:
agent.learn_neural_module(module_name, i, self.world)
else:
agent.load_neural_module(module_name, i)
def run_interaction(self, silent=False):
""" Create a new interaction, make it happen and record the outcome. """
if silent is not True:
fcg.add_element_to_web_interface("<hr/>")
fcg.add_element_to_web_interface("<h1>Starting a new interaction</h1>")
fcg.add_element_to_web_interface("<hr/>")
# Choose 2 interacting agents at random
self.interacting_agents = random.sample(self.population, 2)
speaker = self.interacting_agents[0]
listener = self.interacting_agents[1]
speaker.clear_for_interaction()
listener.clear_for_interaction()
if silent is not True:
fcg.add_element_to_web_interface("<h2>Interacting agents:</h2>")
fcg.add_element_to_web_interface("<p><ul><li>Speaker: " + speaker.id + " </li><li>Listener: " + listener.id + " </li></ul></p>")
# Determine interaction type
interaction_type = self.configuration['interaction'] + '(self, speaker, listener)'
# Create interaction object
interaction = eval(interaction_type)
self.current_interaction = interaction
# Run actual interaction
interaction.interact(speaker, listener, silent)
# Record outcome
interaction.record_communicative_success(self.interacting_agents)
interaction.record_lexicon_size(self.population)
interaction.record_conventionality(speaker, listener)
def run_series(self, nr_of_interactions, silent=True):
"""Run a series of interactions."""
with alive_progress.alive_bar(nr_of_interactions, force_tty=True) as bar:
for i in range(nr_of_interactions):
self.run_interaction(silent=silent)
bar()
def plot_results(self, window_size=100):
pp = make_plot_points(MONITORS, window_size=window_size)
# for each key in plot points (pp), create a plot
fig, axes = plt.subplots(len(pp.keys()), figsize=(5, 7), sharex=True)
for i, key in enumerate(pp.keys()):
ax = axes[i]
ax.plot(list(range(len(pp[key]))), pp[key], label=key)
ax.grid()
ax.legend()
plt.show()
Interaction
At the beginning of a new interaction, two agents are drawn from the population and assigned the roles of speaker and listener. At the same time, three mugshots that were not seen during the prelinguistic stage, and which depict three different people, are sampled from the world. These three images serve as the scene of the interaction and are made visible to both agents. One image from the scene is randomly selected to be the target of the conversation, and is disclosed to the speaker only. The task of the speaker will be to produce an utterance that draws the attention of the listener to the target entity and the task of the listener will be to point at it.
The speaker first uses the neural network that it trained during the prelinguistic stage to conceptualise the target image in terms of an individual person, represented through one of the agent’s internal classes. The speaker then calls its formulate method to retrieve its most entrenched construction that maps between this class and a linguistic form. If there exists no construction in the speaker’s grammar that associates a linguistic form with this class, as will necessarily be the case
at the beginning of the experiment, the speaker will call its learn method to invent such a construction. The linguistic form is then passed on to the listener, which calls its comprehend method to map the observed form to one of its own internal classes. The listener then uses the neural network that it trained during the prelinguistic stage to identify the corresponding individual in the environment. Finally, the listener points at the image in which it recognised the individual, after
which the speaker provides feedback by pointing at the target image. The agents have achieved communicative success if the listener could correctly identify the target entity, and both agents will positively or negatively reward their constructions at the end of the interaction, by adapting the entrenchment scores of their constructions based on whether communicative success was reached or not. If the listener observed a form that was not covered by one of its previously acquired constructions,
it will call its learn method to create a new construction based on the observed form and the feedback that the speaker provided to the listener through pointing.
[8]:
class Interaction:
""" General interaction class. """
def record_communicative_success(self, interacting_agents):
""" Record communicative success of the interaction """
success = all([agent.communicated_successfully for agent in interacting_agents])
if success:
notify('communicative_success', 1)
else:
notify('communicative_success', 0)
def record_lexicon_size(self, population):
""" Record the average lexicon size across the population. """
agents_with_cxns = [agent for agent in population if agent.grammar_size() > 0]
avg_nr_of_cxns = np.mean([agent.grammar_size() for agent in agents_with_cxns])
notify('construction_inventory_size', avg_nr_of_cxns)
def record_conventionality(self, speaker, listener):
""" Record the lexicon coherence between speaker and listener """
if not speaker.communicated_successfully:
notify('conventionality', 0)
else:
listener_form = listener.formulate([["concept", listener.concept]])
if speaker.utterance == listener_form: ##check!
notify('conventionality', 1)
else:
notify('conventionality', 0)
class DescribeAndPointInteraction(Interaction):
"""
Interaction class for description-and-point interactions.
"""
def __init__(self, experiment, speaker, listener):
self.experiment = experiment
self.speaker = speaker
self.listener = listener
self.speaker.discourse_role = "speaker"
self.listener.discourse_role = "listener"
# Load scene and set tasks
self.scene, target_index = experiment.world.sample_scene_with_unique_target(nr_of_entities = experiment.configuration['nr_of_entities'],
train=False)
speaker.task = DescriptionTask(speaker, self.scene, target_index)
listener.task = PointingTask(listener, self.scene)
def interact(self, speaker, listener, silent):
"""Defines the interaction script."""
if silent is not True:
fcg.add_element_to_web_interface("<h2>Scene:</h2>")
for entity in self.scene:
entity = entity * 255
fcg.render_image_in_web_interface(entity.squeeze().tolist())
fcg.add_element_to_web_interface(" ")
# Run description task speaker:
utterance = speaker.task.run_task(silent=silent)
# Pass the utterance to the listener
listener.utterance = utterance
# Run the listener side (parsing and possibly adoption)
understood_target_index = listener.task.run_task(utterance, silent=silent)
if silent is not True:
fcg.add_element_to_web_interface("<hr/>")
fcg.add_element_to_web_interface("<h2>The speaker agent provides feedback to the listener agent.</h2>")
fcg.add_element_to_web_interface("<hr/>")
if speaker.task.target_index == understood_target_index:
speaker.communicated_successfully = True
listener.communicated_successfully = True
if silent is not True:
fcg.add_element_to_web_interface('<p style="font-size:16px;color:green;"><b>Communication was successful!</b>.</p>')
else:
target_entity = listener.task.scene[speaker.task.target_index]
neural_module_name = listener.configuration["primitives"][listener.task.primitive]
listener.concept, _ = classify_image(target_entity, listener.neural_modules[neural_module_name])
mapped_concept = listener.category_mapping[listener.concept]
new_cxn = listener.learn(listener.utterance, mapped_concept) #repeated invention possible!
if silent is not True:
fcg.add_element_to_web_interface('<p style="font-size:16px;color:red;"><b>Communication was unsuccessful!</b>.</p>')
fcg.add_element_to_web_interface('<p>The speaker points to the topic entity:</p>.')
image = target_entity * 255
fcg.render_image_in_web_interface(image.squeeze().tolist())
fcg.add_element_to_web_interface("<p>The listener conceptualises the target in terms of <b>category " + str(mapped_concept) + "</b> and creates the following construction:</p>")
new_cxn.show_in_web_interface()
# Reward the agents, positively and/or negatively
speaker.reward()
listener.reward()
[9]:
class Task:
pass
class DescriptionTask(Task):
"""Given a context of entities, describe a given target entity."""
primitive = "describe"
def __init__(self, agent, scene, target_index):
self.agent = agent
self.scene = scene
self.target_index = target_index
def run_task(self, silent=True):
"""Run description task: conceptualise target entity (classify image) and formulate utterance."""
target_entity = self.scene[self.target_index]
if silent is not True:
fcg.add_element_to_web_interface("<hr/>")
fcg.add_element_to_web_interface("<h2>The " + self.agent.discourse_role + " agent engages in a <b>description task</b>.</h2>")
fcg.add_element_to_web_interface("<hr/>")
fcg.add_element_to_web_interface("<h2>Target:</h2>")
image = target_entity * 255
fcg.render_image_in_web_interface(image.squeeze().tolist())
neural_module_name = self.agent.configuration["primitives"][self.primitive]
self.agent.concept,_ = classify_image(target_entity, self.agent.neural_modules[neural_module_name])
mapped_concept = self.agent.category_mapping[self.agent.concept]
if silent is not True:
fcg.add_element_to_web_interface("<h2>Conceptualisation:</h2>")
fcg.add_element_to_web_interface("<p>The speaker conceptualises the target in terms of <b>category " + str(mapped_concept) + "</b>.</p>")
fcg.add_element_to_web_interface("<h2>Language production:</h2>")
self.agent.utterance = self.agent.formulate([["concept", mapped_concept]])
if self.agent.utterance is not None and silent is not True:
fcg.add_element_to_web_interface("<p>The speaker applied the following construction(s):</p>")
self.agent.applied_cxn.show_in_web_interface()
fcg.add_element_to_web_interface("<p>and utters:</p>")
fcg.add_element_to_web_interface('<p style="font-size:16px;"><b>"' + self.agent.utterance + '"</b></p>')
if self.agent.utterance is None:
self.agent.learn(fcg.generate_word_form(), mapped_concept)
self.agent.utterance = self.agent.formulate([["concept", mapped_concept]])
if silent is not True:
fcg.add_element_to_web_interface("<p>The speaker <b>invents</b> the following construction(s):</p>")
self.agent.applied_cxn.show_in_web_interface()
fcg.add_element_to_web_interface("<p>and utters:</p>")
fcg.add_element_to_web_interface('<p style="font-size:16px;"><b>"' + self.agent.utterance + '"</b></p>')
return self.agent.utterance
def classify_image(image, neural_net):
"""Classify image using neural net, and return label and probability of prediction."""
global DEVICE
image = image.float().to(DEVICE)
output = neural_net(image.unsqueeze(0))
prediction = torch.argmax(output).item()
softmax = torch.nn.Softmax(dim=1)
probabilities = softmax(output)
prediction_probability = probabilities[0][prediction].item()
return prediction, prediction_probability
class PointingTask(Task):
"""Given an utterance and a context of entities, point to the target entity."""
primitive = "point"
def __init__(self, agent, scene):
self.agent = agent
self.scene = scene
def run_task(self, utterance, silent=True):
"""Run pointing task: comprehend utterance and retrieve entity in the scene. Return target index."""
target_index = None
if silent is not True:
fcg.add_element_to_web_interface("<hr/>")
fcg.add_element_to_web_interface("<h2>The " + self.agent.discourse_role + " agent engages in a <b>pointing task</b>.</h2>")
fcg.add_element_to_web_interface("<hr/>")
fcg.add_element_to_web_interface("<h2>Language comprehension:</h2>")
listener_comprehension_result = self.agent.comprehend(utterance)
if listener_comprehension_result is None and silent is not True:
fcg.add_element_to_web_interface("<p>The listener could not comprehend the utterance.</p>")
if listener_comprehension_result:
self.agent.concept = listener_comprehension_result[0][1]
neural_module_name = self.agent.configuration["primitives"][self.primitive]
highest_probability = 0.0
for i in range(0, len(self.scene)):
entity = self.scene[i]
prediction, probability = classify_image(entity, self.agent.neural_modules[neural_module_name])
mapped_prediction = self.agent.category_mapping[prediction]
if mapped_prediction == self.agent.concept:
if probability > highest_probability:
highest_probability = probability
target_index = i
if silent is not True:
fcg.add_element_to_web_interface("<p>The listener applies the following construction(s):</p>")
self.agent.applied_cxn.show_in_web_interface()
fcg.add_element_to_web_interface("<p>The listener looks for an entity of <b>category " + str(self.agent.concept) + "</b> in the scene.</p>")
fcg.add_element_to_web_interface("<p>The listener points to the entity: </p>")
target_entity = self.scene[target_index]
image = target_entity * 255
fcg.render_image_in_web_interface(image.squeeze().tolist())
return target_index
Monitoring and Plotting
[10]:
from itertools import islice
MONITORS = {}
def notify(monitor, value):
""" Notify will add 'value' to the 'monitor' key in the global variable MONITORS. """
global MONITORS
if monitor in MONITORS:
MONITORS[monitor].append(value)
else:
MONITORS[monitor] = [value]
def window(seq, n=2):
""" Returns a sliding window (of width n) over the data from the sequence. """
it = iter(seq)
result = tuple(islice(it, n))
if len(result) == n:
yield result
for elem in it:
result = result[1:] + (elem,)
yield result
def make_plot_points(monitors, window_size=100):
""" Creates a new dictionary with the averages of the sliding windows, using the same keys as the monitors. """
plot_points = {}
for key in monitors:
plot_points[key] = []
generator = window(monitors[key], n=window_size)
for w in generator:
plot_points[key].append(np.mean(w))
return plot_points
Running an experiment
A new experiment can be run by first creating a new instance of the GroundedNGExperiment class, passing the desired configuration.
[11]:
CONFIGURATION = {'learn_prelinguistic_categorisation': False,
'nr_of_epochs' : 5,
'learning_rate' : 0.00001,
'nr_of_agents' : 5,
'cxn_positive_reward' : 0.1,
'cxn_negative_reward' : 0.2,
'nr_of_entities' : 3,
'nr_of_categories': 40,
'world' : 'OlivettiLgData()',
'interaction' : 'DescribeAndPointInteraction',
'neural_modules' : ['DescribeNetOlivetti'],
'primitives' : {'describe': 'DescribeNetOlivetti',
'point': 'DescribeNetOlivetti'}}
experiment = GroundedNGExperiment(CONFIGURATION)
We now run the prelinguistic stage, where agents learn to tell individuals apart. If you want to save some time and electricity, you can also load pre-trained models (for 5 agents - about 5GB download)):
[12]:
# Download pretrained models
models = fcg.load_resource('groundedngmodels.zip', target_directory=".")
if not os.path.isfile('models/DescribeNetOlivetti-4.pt'):
fcg.fcg_go_bridge.unzip(models,".")
[13]:
# Run prelinguistic stage using pretrained models:
experiment.run_prelinguistic_stage(learn_prelinguistic_categorisation=False)
# Run prelinguistic stage from scratch:
# experiment.run_prelinguistic_stage(learn_prelinguistic_categorisation=True)
We run 5000 situated communicative interactions:
[14]:
experiment.run_series(5000)
|████████████████████████████████████████| 5000/5000 [100%] in 5:12.1 (16.02/s)
And we trace the 5001st interaction in the web interface:
[15]:
fcg.start_web_interface()
experiment.run_interaction()
The dynamics of an experiment are continuously monitored while running a series of interactions. The outcome of each individual interaction is recorded by the run_interaction method in terms of three metrics. The first metric quantifies communicative success as a binary measure, reflecting whether the listener agent indeed pointed to the target of the conversation. The second metric records the average number of constructions in the grammars of the agents. The third metric quantifies the
conventionality of the uttered form, reflecting whether the listener agent would have uttered the same form under the same circumstances if it would have been assigned the speaker role. We demonstrate here the use of matplotlib as implemented by the GroundedNGExperiment.plot_results() method, which plots the the degree of communicative success, degree of conventionality and average number of constructions as a function of the number of interactions that have taken place, using a
sliding window of a chosen number of interactions:
[16]:
experiment.plot_results(window_size=100)
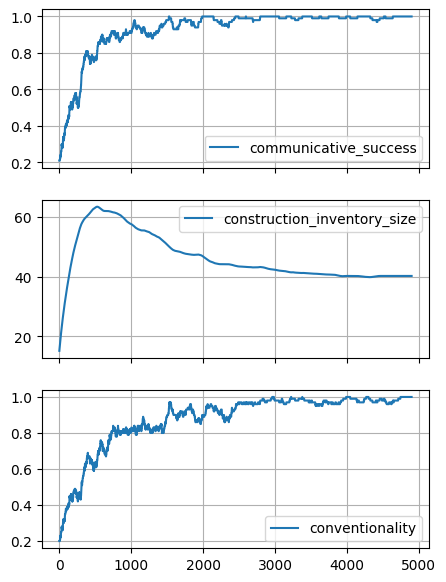
The graphs show that the population indeed converges on a communicatively effective naming convention with one construction for each individual in the world. We can observe the typical language emergence dynamics known from the evolutionary linguistics literature, where the degrees of communicative success and conventionality gradually increase as more interactions take place, while the average grammar size overshoots in the early stages of the experiment, before gradually decreasing as the conventionalisation process further unfolds.